
OceanCanada

Role
Design Researcher and Information Designer
Platforms
Web, WordPress
Scope
Content Systems, Design Strategy, Systems Design, Information Design, Data Visualization, Information Architecture, Admin Enablement
Designing a knowledge translation platform for the interpretation and dissemination of scientific research.
Problem framing
OceanCanada is a national research partnership producing peer-reviewed work on fisheries, ocean ecosystems, climate change, and coastal communities. Despite strong research output, the organization faced a familiar challenge in high-accountability, data-heavy environments:
Critical information existed, but the system did not consistently enable correct interpretation, publication, or reuse by non-experts, including the public, students, policymakers, and organizational staff.
This project approached knowledge translation as a product and systems problem, not a content problem.
Within OceanCanada, knowledge translation relied heavily on individual judgment, manual effort, and tacit expertise held by a small number of people. This created variability, bottlenecks, and institutional risk. The outcome was a scalable, governance-aware platform concept that enabled public users to understand complex scientific research without domain expertise, researchers to preserve scientific integrity, non-design, non-UX admins to curate, translate, and publish content independently, and the organization to operate within copyright, credibility, and institutional constraints.
Design problem
This work extended beyond end-user usability into organizational enablement. Key characteristics of the problem included:
Multiple user types with different authority and accountability
Information where misunderstanding had real reputational and societal consequences
Publishing workflows owned by non-design, non-research staff
A need for consistency and trust over time, not one-off engagement gains.
Design question
How do we design a system that enables correct decisions at scale by people who are not designers, researchers, or technologists?
Constraints
This project was shaped by non-negotiable constraints common to high-accountability information systems. These constraints defined the design space and informed every structural decision.
Technical constraints
Implementation limited to UBC’s WordPress-based CMS
No custom backend services or automated ingestion pipelines
Design solutions had to align with existing CMS patterns and permissions.
Operational constraints
Administrators manually populate publication pages
Content sourced from peer-reviewed articles and academic books
Admins have no formal training in UX, data visualization, or knowledge translation.
Interpretation and data constraints
Visualizations generated from a controlled, preset taxonomy of fisheries and ocean-science keywords
Keyword lists designed to preserve semantic accuracy, prevent speculative interpretation, and maintain consistency across publications.
Design objective
Embed knowledge translation into the platform, so that correct interpretation and publication decisions emerge from the workflow.
Note: Success was not defined by visual polish, but by reduced ambiguity for admins, consistent outputs across time and contributors, lower cognitive and operational load, and preservation of scientific credibility.
Research and synthesis
I led synthesis across a design study process combining surveys with students and general audiences, exploratory sketch exercises to understand sense-making, workshops with OceanCanada researchers, and usability testing across expertise levels.

Key insights
1. More information reduced engagement when context was missing
Users needed relevance before depth, orientation before detail, and multiple, intentional entry points.
Design requirement: The system must stage understanding, not simply expose data.
2. Knowledge translation is a workflow and governance problem
Researchers identified five recurring areas of action:
Communicating research outside academia
Simplifying without distorting meaning
Public outreach via alternative media
Information verification across channels
Coordinated knowledge dissemination.
These insights translated into design requirements focused on information practices, not just interfaces, including navigating multiple levels of complexity, enabling semantic consistency across media, validating information relevance, and supporting timely, coordinated publishing.
Design requirement: The system must enable good knowledge-translation behaviour, rather than depend on individual expertise.
Design strategy: decision-making and admin enablement
Admins were treated as decision-makers, not content uploaders. The system enabled them to:
Identify which elements of a publication were relevant to non-expert audiences
Associate content with predefined topics and regions
Publish at appropriate levels of complexity
Maintain semantic consistency without UX or research training.
Aligning UI language with institutional realities
We designed several screens in low and high-fidelity mock-ups to show users for feedback.
Low fidelity sketches
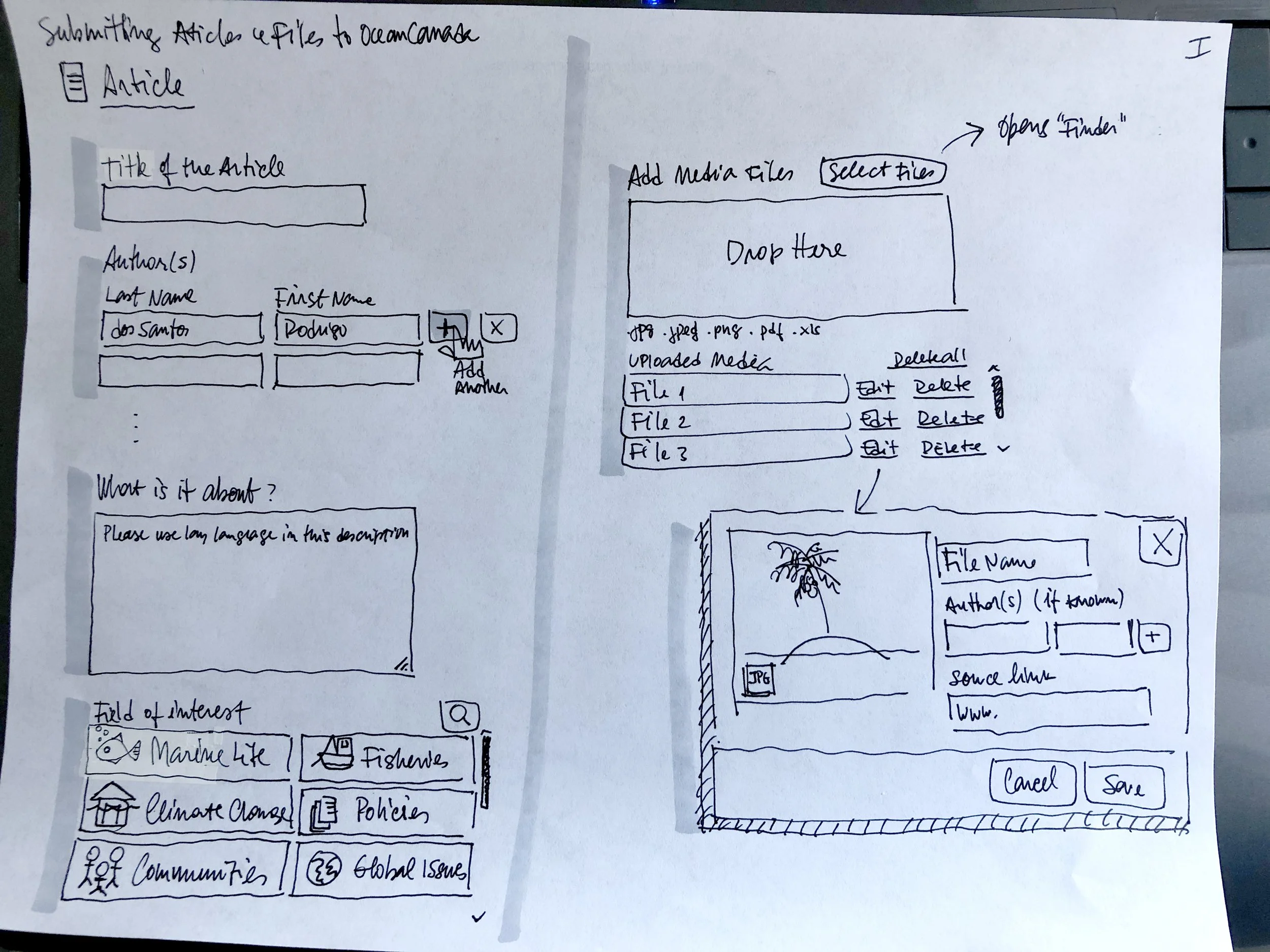
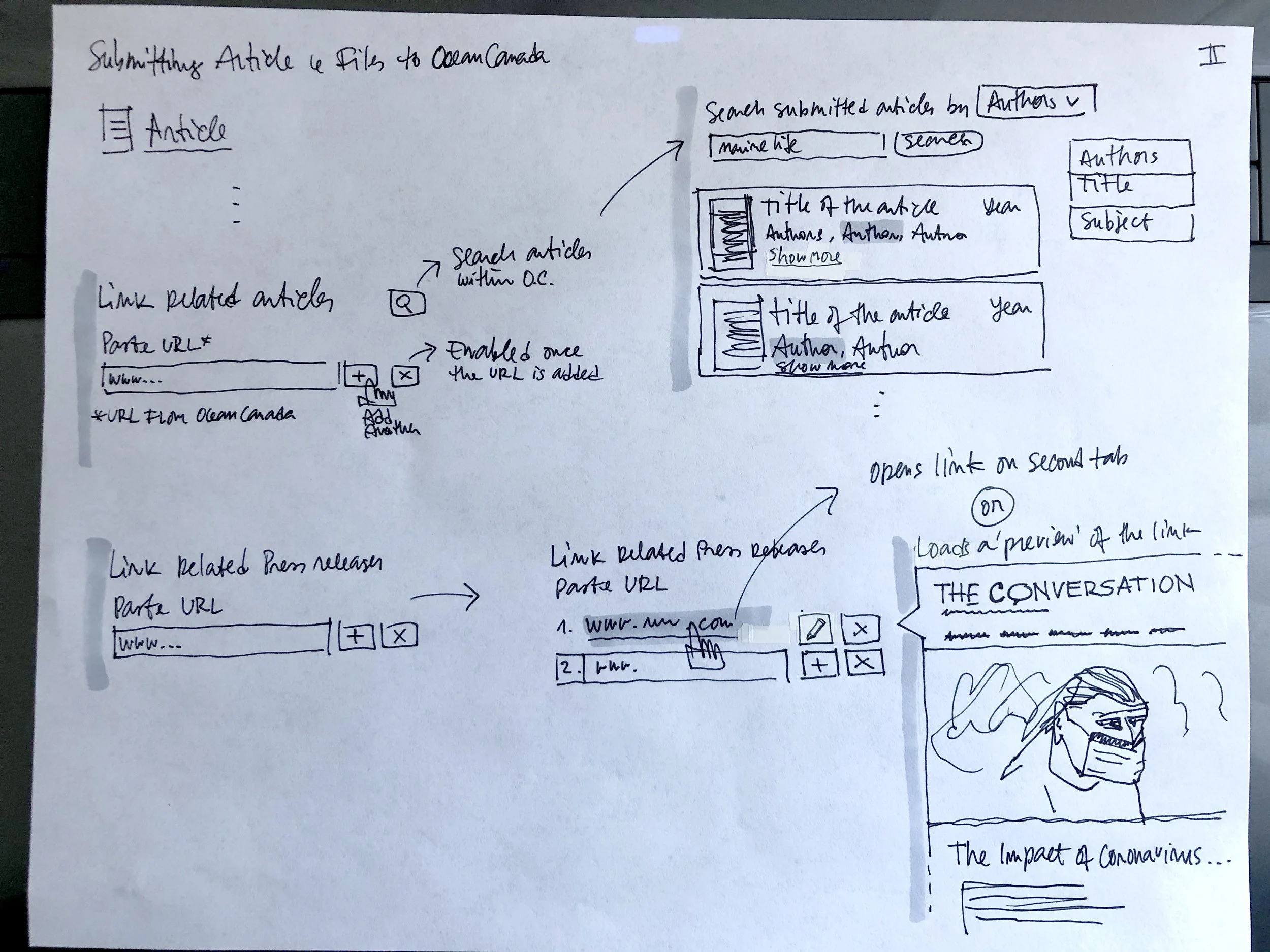
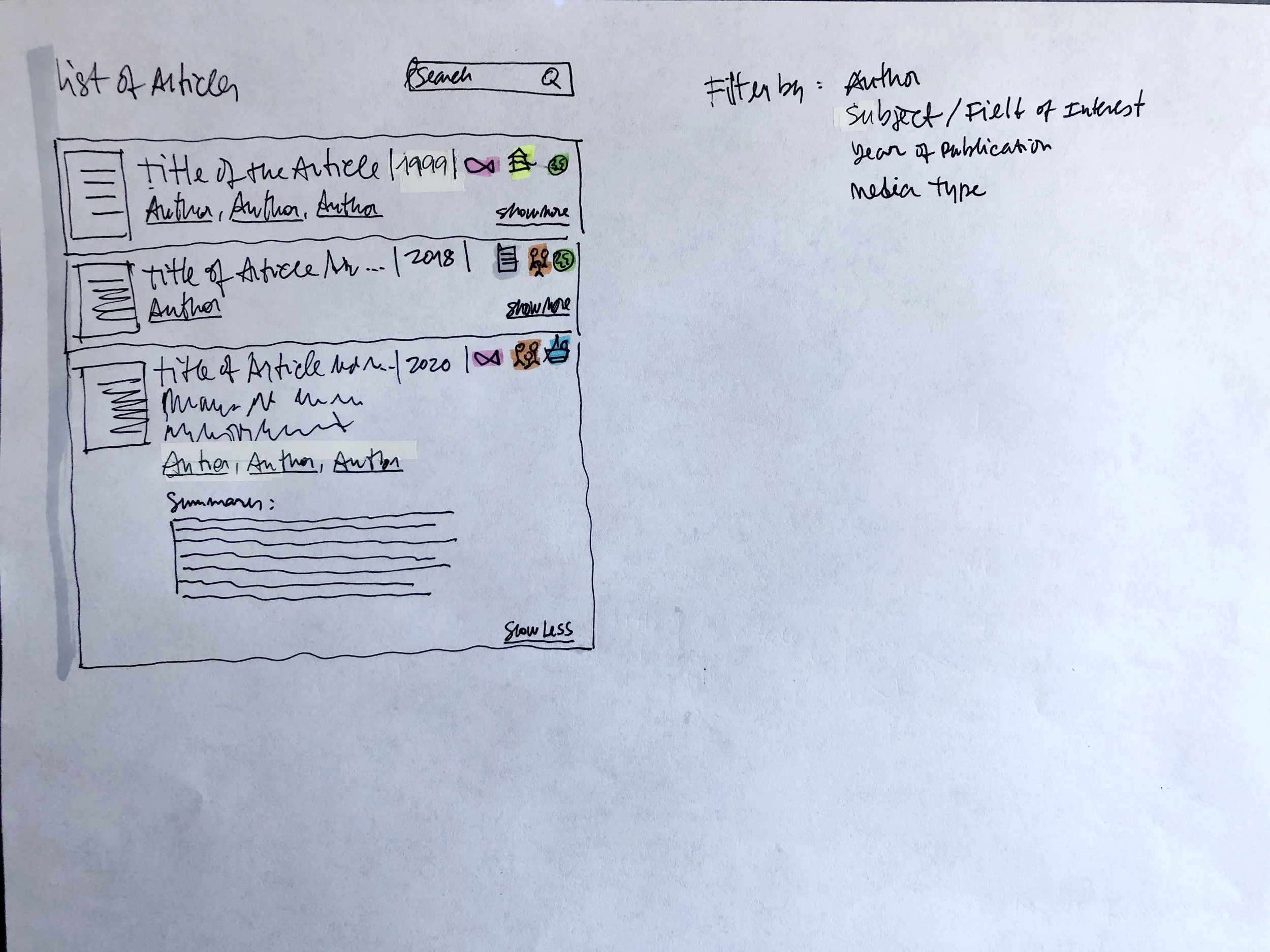
Article page wireframe
Visualization supporting interpretation
Visualizations functioned as interpretive aids, not analytical endpoints, reducing misinterpretation while preserving meaning. Design choices included:
Controlled keyword taxonomies
Explicit legends and instructional cues
Visual hierarchy emphasizing relationships over metrics.
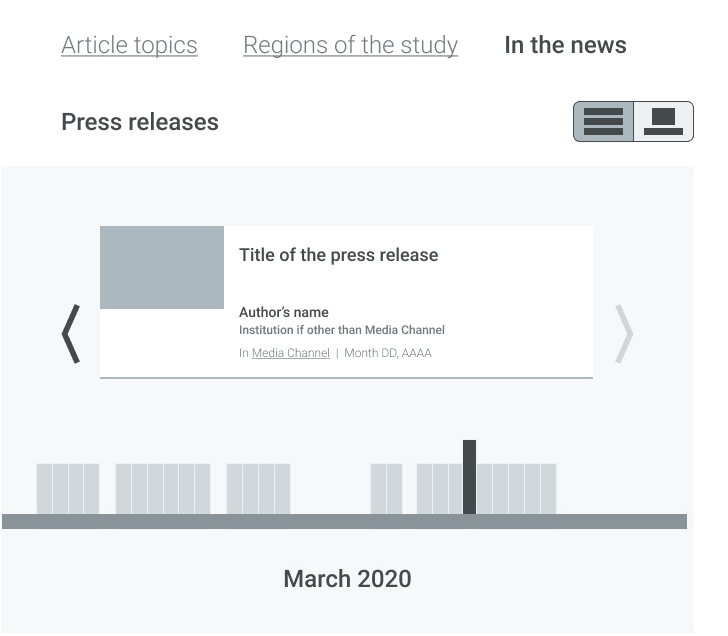
Timeline of press releases about the article.
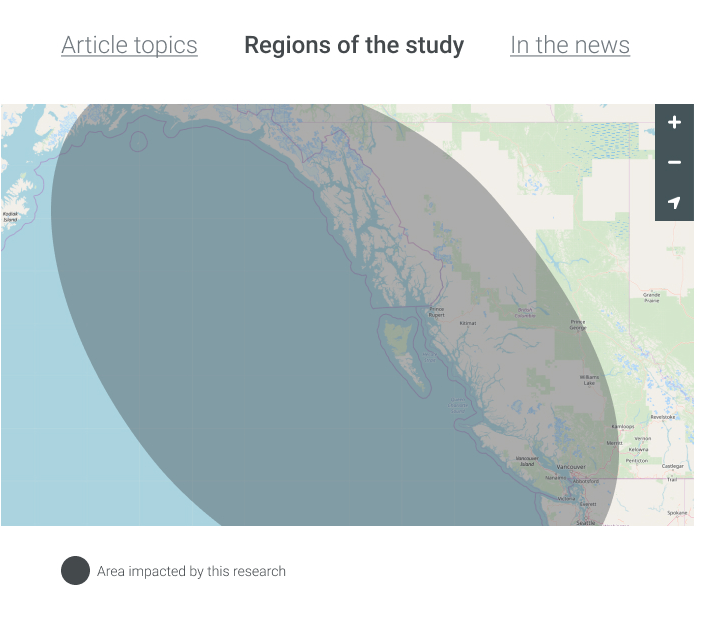
Marked area indicates the geographical regions affected by the research.
Outcomes
Organizational outcomes
Reduced reliance on specialized expertise
Increased consistency and reliability in published content
Improved alignment between researchers, admins, and public audiences.
Platform outcomes
Shift from static repository to interpretive system
Knowledge translation embedded into everyday workflows
A model that scales through structure rather than training.
Validation and iteration
Usability testing showed that visual summaries lowered entry barriers, filters significantly improved discovery, and users required explicit guidance to interpret charts correctly. Iterations focused on: clarifying semantics, improving regional context, and distinguishing open-access vs. restricted content.
Future considerations
While automation was limited at the time of the project, the platform was intentionally designed to be extensible. Its structured content model, controlled taxonomies, and decision-oriented workflows create a strong foundation for responsible system-level augmentation.
Today, a combination of AI and deeper system integration could further reduce cognitive load, improve consistency, and strengthen governance, while preserving human accountability. A few orientations include:
Integrated metadata extraction from reference managers
Integration with reference management tools (e.g., Zotero, Mendeley) could enable, automatic extraction of article metadata (authors, publication date, journal, DOI), reduction of manual entry errors, and faster, more consistent population of publication pages. In doing so, the system could enable admins to spend less time transcribing information and more time validating relevance and context.Built-in author permissions and validation workflows
The system could support, structured permission requests to article authors prior to publication, inline validation or feedback loops for summaries and interpretations, and clear visibility into approval status within the CMS. System Governance and credibility are enforced through workflow, not informal coordination.System-generated keywords (human-reviewed)
Building on the existing controlled taxonomy, the platform could suggest keywords derived from article content, constrain suggestions to approved vocabularies, and require explicit admin confirmation before publication. System consistency would be improved without removing editorial judgment.Expanded chart types and controlled customization
Additional visualization types and limited customization options could be introduced, incorporating alternative chart forms selected based on content type, guard-railed configuration (e.g., scale, grouping, emphasis), and presets designed to prevent misleading representations. Admins could gain expressive flexibility while the system prevents risky interpretation.Geographic relevance and impact visualization
The platform could more explicitly surface geographic context by visualizing where studies were conducted, indicating regions or communities impacted by the research, and supporting multiple geographic layers (local, regional, global). In doing so, users would gain situational understanding without requiring deep domain knowledge.AI-generated lay-language summaries
Building on the original knowledge-translation goals, AI tools could draft plain-language summaries from scientific text, highlight assumptions, limitations, and uncertainties, and flag areas requiring human review before publication. The system would support admins in translation tasks without delegating authority to automation.
In all cases, AI features act as decision support, not autonomous publishing mechanisms. Human review, approval, and responsibility would remain explicit and traceable.
Takeaway
This project reframes a public-facing research platform as a high-accountability decision-making system. The design prioritizes operational consistency, governance, and decision quality, enabling non-expert operators to publish and maintain complex information responsibly under technical and institutional constraints.